The biggest indicator of the success of AMD Threadripper line to me is that Intel has been forced to cut the price of their newly released i9-10980XE CPU by $1000 compared to i9-9980XE while maintaining practically indistinguishable performance.
And that's just cheating anyway. Intel's libraries refuse to use some instructions on AMD's CPU that the CPU supports, and instead downgrade to slower legacy versions. Cite[0].
The first problem is that AMD does not provide versions of those libraries tuned for AMD hardware. The investment of AMD into software for their hardware is close to zero, and without software, hardware is irrelevant. AMD has this problem when competing against nvidia in the GPU space, and against intel in the CPU space.
The second problem is that buyers of AMD products demand that Intel would release their software optimized for AMD products as well, which is just nonsensical. First, Intel is not required to do this and have no reason to do so - if this software doesn't work for your hardware, either buy Intel, or use something else. Second, these people don't expect AMD to provide these libraries, and aren't willing to provide them themselves, so... combined with AMD culture of not investing in software, nothing will happen.
That link is 10 years old, but these issues are at least 10 years older. That is, AMD has had 20 years to fix this, and nothing has happened.
I mean, this might sound like captain obvious, but Intel and Nvidia have super good profilers for their hardware (VTune and Nsight). AMD provides uProf, which sucks, so if that is what their engineers are using for their libraries, it isn't a surprise that they don't perform good.
When writing optimized code you typically check for CPU feature before CPUID, and profile to verify that it actually is faster.
In Intel's case, libraries like MKL/IPP don't decide which implementation to use based on available features but CPUID, and fall back to slow versions even if the CPU supports all features required for the optimization.
There's nothing stopping Intel from providing fast libs that are optimized for their hardware, profiled on their systems, and utilize all the secret sauce they want while still being more or less "fast" on AMD.
But all that said those libs aren't especially compelling when there are alternatives that may be a bit slower on Intel but kick ass on AMD, when a non-zero segment of users are transitioning to the better value processors today.
> In Intel's case, libraries like MKL/IPP don't decide which implementation to use based on available features but CPUID, and fall back to slow versions even if the CPU supports all features required for the optimization.
The CPU features indicates if a feature is available, but doesn't indicate if it's advisable or fast -- that's why Intel built a table for their hardware, and they'd need a table for AMD hardware too, except they don't care, because it's not their hardware. AMD or someone could build that table and patch it in, or try to convince Intel to include it, but expecting Intel to build it themselves is wishful thinking at best.
"and they'd need a table for AMD hardware too, except they don't care"
They very much do care, and that is amply evident. Every other compiler uses feature detection or developer intention (e.g. if I say use AVX, use it or crash). Intel actively and intentionally -- with intent -- sabotages performance on AMD devices.
This is where the market decides, however, and it's why the intel compilers and libraries are fringe products, and their software division is effectively a disaster. If you have a specific HPC setup with Intel processors maybe you'll cross compile with them, but most simply steer far clear of them. For a while Intel sold them as a software vendor -- not as some sort of coupled processor support -- and many learned they aren't trustworthy.
> Every other compiler uses feature detection or developer intention
ICC has tons of built-in functions like _mm_div_epi32, _mm256_log10_ps, _mm_sin_ps and many others. These are not hardware intrinsics. These are library functions. Other compilers don’t need to feature detect because unlike Intel’s they don’t have these functions in their standard libraries: no exponents/logarithms, no trigonometry, no integer divides, nothing at all on top of the hardware instructions.
I mostly use VC++ and I had to implement these functions more than once. Funny enough, AMD’s SSEPlus helped even on Intel, despite AMD abandoned the library a decade ago.
> The second problem is that buyers of AMD products demand that Intel would release their software optimized for AMD products as well, which is just nonsensical. First, Intel is not required to do this and have no reason to do so - if this software doesn't work for your hardware, either buy Intel, or use something else.
While Intel isn't REQUIRED to do so, it absolutely is a sensible thing to do. If my customers need something, I want to provide it to them. If my customers want me to add a feature that makes their products run well on competitors' CPUs, then its in my best interest to make that happen, if I can get the other CPU maker to give me the data I need. This makes my direct customer happy, makes me look good for prospective customers, and builds loyalty to my brand. It also makes my customer happy by making THEIR customers happy, which keeps them customers of mine.
All of those points would be a lot more relevant if Intel were a software company, or if it at least got a significant portion of it's revenue from software sales. I very much doubt that's the case though.
Intel is very much of the mindset of that it is a silicon company selling hardware and everything else is accessory to that. The software is just inducement to use the hardware. Users of the compiler are not inherently customers; they're only customers if they're using the Intel compiler on Intel CPUs.
Yes, it's a weird mindset for a company that employs a lot of software engineers.
While I would like this issue resolved I'm not sure I follow your logic at all that Intel should be the people to fix it.
When there are only two viable options in a marketplace, offering improvements to make your direct competitor's product better than yours is shooting yourself in the foot.
Your point about happy customers would make sense if Intel was selling all manner of service contracts and extraneous engagements with it's consumer base, but is it?
I'm pretty sure the chip business is speed / cost and that's all.
What's ironic is that AMD knows better than any tech company I can think of exactly what the rewards are for coming second in the chip game.
I totally buy that Intel should use the feature flags instead of checking the CPUid name for stuff like AVX, FMA, etc...
However, ICC does support several advanced optimisations whereby it literally schedules instructions based on expert knowledge of architecture cycle latency and number of ports: LLVM and GCC have similar tables for overall stats which I think AMD contribute to, but ICC can also hook in memory and cache bandwidth / latency to schedule instructions: this by definition would need to be Intel-specific, unless AMD were happy to give Intel this information.
So some of the optimisations are by definition Intel-only.
The question really is how fair should the fall-backs be.
Yes, but if you're interested in performance, it's very possible that using the wrong scheduling of instructions for those particular optimisations (very particular scheduling ones) will result in extremely bad performance due to pipeline stalls, so running the machine code on the wrong architecture (possibly even among Intel platforms) will not give good performance other than on the explicit machine it's optimised for.
Keep in mind that ICC supports dynamic code paths for different marchs, so in theory you could have code for Intel 6th Gen, 7th Gen, 8th Gen, etc all dynamically switchable at run time.
Given how a modern high perf processor work, I don't expect that at all. Moderately bad performance in some extremely rare cases, and comparable performance in most, is WAY more probable. Better performance in some cases is also possible.
If you don't know the microarchitecture enough, you can also just look at benchmarks of Zen processors. They are vastly running code non-tuned for it, and for some loads I expect the code was actually tuned for Skylake, given all desktop Intel processors have been Skylake microarch for a non trivial number of years. It performs well on Zen.
For highly-tuned code, it's fairly trivial to find cases where data alignment and the amount of loop unrolling compilers do can have significant differences between microarchs.
Whether it's to do with cache associativity, different cache / instruction latencies or number of ports between CPUs or things like false-sharing, it happens enough that it's worth doing per-CPU optimisations.
One of the reasons Zen2 runs code likely not directly optimised for it so well is likely because AMD's microarch is now quite similar to Core now (at least within the chiplets).
Previously, with things like Bulldozer, that was most definitely not the case, and you needed quite different instruction scheduling code to perform even moderately well on AMD machines of 5/6 years ago.
An enthusiast looking at published benchmarks is going to have a very different idea about what "highly-tuned" really means than the guys in the trenches spending lots of time profiling and making hardware sing.
> An enthusiast looking at published benchmarks is going to have a very different idea about what "highly-tuned" really means than the guys in the trenches spending lots of time profiling and making hardware sing.
That's actually what matters and drives the market (the capability to run very diverse general purpose loads with a reasonably high efficiency). If expert hand tuning to each microarch (and actually the whole computer around it) was required, Cell-like things would have won, coherency would be low, and so over.
You don't have that; the whole Earth use x64 for general purpose high perf, or other ISA but now the microarch is very similar for everybody. Oh yes, you will still find some differences and tuning points here and there, but the general principle are all the same, and any precise tuning will be as a rule of thumb as fragile as the gain it gives are impressive. Robust good enough perf is WAY more important. You don't want to fine tune all the programs again just because you went from 2 memory channels to 4.
I mean it is well known that we are at the point where random code offset changes give more perf diff than fine assembly adjustments in some cases, and there is even tooling to do diverse layout to empirically try to find out if perf diff of two snippets are by chance because of very indirect factors, or intrinsically one is better than the other. And except for VERY specific application, there is absolutely no economic sense in trying to get the last perf bits of a specific computer by trying to hand-tune everything at low level. Those modern beast do it dynamically largely well enough, in the first place.
Now I understand that this art still exists and TBH I sometimes even practice it myself (moderately), and if you actually are going to deploy some cool tricks to a fleet of similar servers, that can make sense. But in the long run, or even just medium, the improvement of the CPUs are going to "optimize" better than you are, like usual. So while I'm not saying "don't micro-optimize ever", I actually insist that Zen 2 is extremely decent, very similar to Skylake (not just Core, even the state of the art Skylake improvement of it, Ice Lake does not really count yet) even if it also have drawbacks and advantages here and there, and that the general purpose "enthusiast" benchmarks simply reflect that. And some of the loads in those benchmarks are actually programmed by quite expert people too.
Now if you have really really precise needs, fine, but I mean that's kind of irrelevant, you could also say "oh but all of that is crap, I need a shitload of shitload of IO and my mainframe is really cool for that, plus I'm an expert on this family since 20 years and now all the details of where it shines". Yeah, that can be an existing situation too. But not really where the fight is playing right now, for most people.
Because in many countries, including US, it's illegal to leverage one product to ensure unfair market advantage for your other products, and this is very close to that...
Intel spent money to prevent their competitor from leveraging speedups from their compiler. It would have been less work for them to simply use feature detection on AMD chips, since Intel already has to implement feature detection for their own chips.
CentaurTechnologies ran benchmarks against ICC with the CPUID set to the default and then with it set to the name of an Intel chip with equivalent CPU flags.
Intel's response was roughly "We don't trust CPU flags, so we have kernels for each specific Intel chip, and a generic kernel for non-Intel chips"
You're looking at this from the perspective of someone who is actually using this specific library. The issue is that it's cheating on a benchmark.
The large majority of the code people actually run isn't written by Intel or AMD. We use benchmarks for comparison because it gives people an idea of the relative performance of the hardware. Reviewers are not going to test the hardware against every individual piece of line-of-business software or in-house custom code that people will run on the hardware in real life, so instead you get a sample of some common categories of computer code.
Optimizing the benchmark for one architecture and not the other is cheating because it makes it no longer a representative sample. Real third party code is generally not going to enable instructions only for Intel and not AMD when they exist (and improve performance) on both, it will either use them on both or not at all.
So you want that all binaries are packaged in 2 formats, one for AMD and one for Intel, basically all binaries will be double in size? Imagine Google code would detect if you run on Chrome and use native functions but for other browsers(including Chromium forks) will just load polyfils because checking if the feature exists is too much to ask.
>o... combined with AMD culture of not investing in software, nothing will happen.
That is just not true, they work on the open source toolchain like LLVM and GCC and hopefully things will catch up. And as far as I can tell things are getting much better in 2019.
They commit patches to OpenBLAS which is still 2-3x slower on Zen 2 than MKL on Intel hardware. Intel has better software engineers for high-performance math it seems.
I think much of that will flow into their GPU department. They have the node advantage compared to Nvidia (TSMC 7nm vs. TSMC 12nm) but can only match Nvidia in power consumption and performance. Once Nvidia get's to 7nm with their new architecture they will increase the gap again (unless RDNA2 which is rumored for H1 2020 brings a big efficiency and performance improvement - and not only hardware accelerated RT).
But yes, they are generally way behind in this area, and in my domain (genomics) this is a serious barrier to adoption. I've been waiting for years for good-enough AMD-optimized linear algebra libraries, but distribution of Linux binaries statically linked to Intel MKL is still the obvious best choice as of November 2019, and that's a shame.
MATLAB (which I think uses Intel MKL) showing faster performance for Intel than AMD but apparently due the above issues of the MKL libraries not utilising AVX on AMD processors? Is this correct?
See my other post on this thread. There's a Zen2/Rome/Ryzen 3xxx optimized compiler, lapback/blas, libm (math), random number generations, and others available.
Desktops is relatively low growth and Intel holds a lot os sway with major integrators. There are about a handful of AMD offers at Dell or Lenovo and dozens of Intel ones.
I wanted one now. And yeah, the future is always brighter.
My current laptop- an HP Pavilion 2000 has an AMD APU as well- but it's from like a decade ago and it's been showing it's age for quite a while, and I needed something newer.
You think that's bad? Try getting Intel libraries like Embree to compile on PowerPC/OpenPOWER systems. It seems designed to be almost entirely impossible to port to new architectures... just about every piece of software released by Intel is made like this. SMH
TBB has support for PowerPC and Sparc: Intel accepted patches.
It's not that difficult to port Embree to other architectures, at least for the 4-wide stuff: you just need intrinsics wrappers, and a bit of emulation for the instructions PowerPC doesn't support.
afaict, the thing uses multi-templated indirected hardcoded asm inlines instead of intrinsic calls - it is not "that difficult" but it is by no means simple and they've done precisely zero favours to anyone trying. They've really gone out of their way, with Embree, to make it crazy hard, if not impossible, to fully activate the built-in SSE/MMX to AVX compatibility shim headers GCC ships with too, where they even can be.
To fix MKL for AMD Rome/Zen2 just do
"export MKL_DEBUG_CPU_TYPE=5"
This helps quite a bit with Matlab (which uses MKL) as well.
For Blas/Lapack like libraries look for Blis and libFLAME.
Gcc-9.2.0 isn't bad, but if you want Zen2/Rome/Ryzen 3xxx optimizations I'd recommend AMD's AOCC, which is a tuned version of LLVM (including c, c++, and fortran).
If you need FFTs look at amd-fftw.
Basic low level math (pow, log, exp, exp2 and friends) library look at the "AMD Math library (libM).
It's only cheating if there exists an alternate compiler that works better on AMD.
It may be not-nice for Intel to use this form of "DRM" to lock their high-performance compiler to Intel chips, but they don't owe AMD users a high-performance compiler.
Now, if vendors are shipping pre-compiled software that has the enabled-for-Intel-only fast-paths and don't ofter AMD-optimized versions, those vendors are misbehaving (intentionally or not).
I agree. It's funny that the lack of attention of AMD to software / drivers (say Blas / MKL, CUDA) is holding the adoption of their silicon back in certain markets even after they've surpassed Intel in performance.
Is avx512 an advantage really? Iirc the machine has to go into another mode where processing across the board becomes slower except for the avx instructions, which to me seems only useful for niche hpc "measuring contest" applications.
AVX on Intel can have unobvious performance degradation: a single AVX512 instruction runs at ¼ speed[1] until the core downclocks, and it stays downclocked for 2ms (severely affecting mixed loads). The downclock apparently takes 500us[2] (edit: fact check? This seems unbelievable), and the CPU is idle until it restabilises.
If AMD have made different choices about AVX implementation, then benchmarking becomes difficult.
Intel benchmarks for sustained AVX512 load (HPC measuring contests) cannot be used to extrapolate for normal mixed loads (single or or short bursts of AVX512 instructions).
Edit: are there better links on the true costs of AVX512?
Not game physics, as it puts the CPU in a lower speed regime it'd have negative implications on the rest of the games performance. So far, that AVX512 requires this lower speed (due to thermals) is an implementation detail, and it could be expected that newer processes (Intels 10 or 7 nm?) would allow them to work AVX512 tasks on full speed.
Until that happens, and everyone has AVX512 (because it'd be a massive fail to have a game that requires you to have a HEDT Intel processor to play), it'd be a nice gimmick to have on very specific tech demos, and performance sensitive scientific code that you know will run on a certain machine with certain characteristics.
Games will ship with AVX512 special paths once the AMD chips in consoles support it. Until then it is just a fancy feature to make already fast CPUs a bit faster.
Game programmers will put time into making slow CPUs faster. Outside tech demos or hardware marketing tie-ins no budget is allocated to making yet more spare capacity.
What kind of games care about such specific instructions? Unless you are writing something in assembly, that's not something game developers usually are focused on.
All kinds of games use AVX. Particularly, anything using Denuvo won't run without it.
AVX-512 isn't just wider execution units, it's different types of instructions, particularly some that fill in holes in the existing sets of instructions. Once it starts to be widely available, it will get used, and will eventually be a requirement, just like AVX has.
Ice Lake is introducing AVX-512 on Intel mobile, Tiger Lake will introduce it on desktop, presumably Zen3 will be introducing it on AMD.
Unity is a very high level engine, that uses C#, and it now has a system built in that lets you write code that looks like C# but will translate it to whatever SIMD instruction set is available, like ISPC.
There are also various libraries that leverage metaprogramming to do similar things. I don't think you understand what game devs are willing to do, to get a few more polygons and pixels on the screen!
> I don't think you understand what game devs are willing to do, to get a few more polygons and pixels on the screen!
Totally depends on the trade-offs. You can write your whole game in assembly, and target very specific hardware, and may be beat optimizing compiler (doubtful). But at what cost? Time spent on that could be spent on making more games.
Normal up to date hardware handles games just fine, as long as they are not using some abysmal and poorly parallelized engines. Modern CPUs with more cores are also helping that, especially after Ryzen processors opened the gates for it.
And specifically the next generation of consoles is using Zen2 architecture, which does not support AVX-512.
That said, desktops can apply whatever optimizations they want. Denuvo uses AVX in their DRM, which is also not a thing on console, so presumably they will eventually incorporate AVX-512.
downclocking is per core, it should normally be very simple to get huge net speedups with AVX-512 despite the downclocking, in game physics or anything else.
its also relatively common to write multiple versions of SIMD code (or use tools like ISPC or metaprogramming) to leverage whatever SIMD instruction set a cpu has. Such as the DOTS system in Unity. Games will happily leverage AVX-512 as soon as a fair number of desktop cpus support it.
From a developer perspective, yes. If you're manually writing AVX intrinsics instead of just relying on the compiler, AVX512 is quite exciting due to the added mask registers, allowing you to exclude certain elements of your vector from the operation.
You can archieve this in AVX2, but it's quite painful.
Example:
Let's say that, for whatever reason, you have a vector struct containing 3 doubles, and another 64 bits of arbitrary data. Now, if you want to add those vectors together, keeping the arbitrary data of one element, that's quite difficult to do with AVX2. In AVX512, you can just set the bits of the mask to zero to exclude them from the operation, making it trivial.
> Example: Let's say that, for whatever reason, you have a vector struct containing 3 doubles, and another 64 bits of arbitrary data. Now, if you want to add those vectors together, keeping the arbitrary data of one element
What? That's just a _mm256_setzero_pd (set the whole register to zero), _mm256_maskload_pd (load the 3 doubles, ignoring the 4th load), and then _mm256_add_pd (4x double-precision add).
AVX had mask instructions, but they took up all 256-bits. AVX512 mask instructions are exciting because they only use 1-bit per mask. A 64-bit mask can cover 64-bytes (aka: 512-bits) of masking.
> only useful for niche hpc "measuring contest" applications
It's useful for crypto. I haven't measured myself, but I expect AVX-512 roughly doubles the throughput of ChaCha20. (Not only do you have 2x as many lanes, you also have new bit rotation instructions.) Something similar applies if you use a tree hash like KangarooTwelve.
Whether your application is actually bottlenecked on crypto performance is another question of course.
avx512 is a spectacular instruction set and absolutely speeds real world workloads up a ton, and makes it easier for compilers to auto vectorize too. the only catch is that is is new so not many things leverage it yet.
Because of the throttling penalty it's often worse for a compiler to produce avx512 code. It's only worth it for very specialized tasks, not even gaming. This may change when throttling is no longer required on newer process nodes. But for now, it's mostly a gimmick.
There's a lot of convenient new instructions in avx512 that can work on 128/256-bit vectors. I'm guessing that those wouldn't throttle more than regular avx.
how often? what suite of code did you benchmark?
Why wouldn't it be good for gaming? Put the AVX-512 workload on one core for just that. Or batch the AVX-512 work together so it isn't short bursts.
Nobody is even thinking about leveraging this stuff without understanding things like this anyway.
Show me a game that uses the actual zmm register operations. The big thing is your game has to run at good frame rates without it, so there's little incentive to optimize something to use them, and if you do the speedup is partially mitigated by the throttling anyway. A lot of work for no gain.
In not saying you can't find something in a game to speedup with avx512, but that you wouldn't want to do that in the first place.
I was just talking about this the other day on reddit. That situation was overblown. Cloudflare were cheaping out, and using chips that _weren't_ recommended or designed for use with AVX-512, and then being surprised that they weren't getting good performance out of it.
Note that for most AVX workloads, it's fine. AVX2 sees a very minimal clock speed drop until almost all cores are actively engaged in the work. It's also worth mentioning that since Haswell days, the CPU groups cores doing AVX work together, to reduce the likelihood of the downclock impacting non-AVX work (I am somewhat curious what the impact on L1 / L2 caching is from that).
AVX-512 is where it can hurt, but it really depends on the workload. Lots of AVX-512 instructions and you're fine, the throughput of the AVX-512 instructions is higher than scalar or AVX2 instructions, even with the down-clock.
The important thing to note here, is that Cloudflare went with what amounts to a bargain basement server CPU. It's almost on the absolute bottom end of the range, and it's a chip not designed for AVX workloads (or indeed anything resembling high performance work). Just take a look at the product brief from when the family was launched (page 8): https://www.intel.com/content/dam/www/public/us/en/documents...
Notice that it can handle a fair level of AVX-512 instructions before it down-clocks, and even then it takes a while before the down-clocking amount is significant, and it can handle significant AVX2 workloads before the maximum frequency gets affected at all (at the point where AVX2 starts causing it to down=clock, you'd be more than reaping the benefits of the faster instructions).
For just a few hundred more dollars: https://en.wikichip.org/wiki/intel/xeon_gold/6126#Frequencie..., you can be utilising all the cores doing AVX-512 instructions and still be faster than the not-designed-for-the-workload chip that Cloudflare cheaped out on.
Note: These extra costs on CPUs are negligible when you take in to account depreciation, server lifetime etc. The biggest lifetime cost of a rack of servers in production is never the cost of the servers. It's your other OpEx. Cheaping out on server processors is a perfect example of what AWS employees call "Frupidity": Stupidity through Frugality. (Frugality is a leadership value in AWS, and sometimes it leads to the most phenomenally stupid things happening)
You can be using all cores with AVX-512 instructions, and see a drop of only 300Mhz, on the entry level platinum chip from that same year as Cloudflare's chip.
I'm not 100% convinced by the 5115 vs 4116, but that will depend on the workload. The case is clear for the 6126, but "For just a few hundred more dollars" is a bit dishonest; you are talking about $1000 (for the 4116) vs $1770 (for the 6126). Now IF you are going to do AVX2/AVX512 like crazy and have the money, sure, go for it. But it is not a case of "oh but for just a little bit more, I've got way much better". And that's even considering other costs. Cause you can use that reasoning for all components, so in the end does ×1.7 really not matter? Not so sure... Hey even $770 vs. amortization through increased performance can be difficult to reach sometimes - that's also very workload / business model dependent.
Also if you actually needs tons of processors, availability might be an issue.
Now in the end, I'm not familiar enough with Cloudfare needs and I know that pretty much anybody can make mistakes, so it is possible that they should have gone with something like the 6126 instead of 4116. But then the 8124? hm, less probable.
Also bare in mind those are RRPs, which Cloudflare likely isn't paying, especially at the scales they're operating at.
The crux of the point was that they were apparently surprised when a chip that wasn't designed for the kind of workload they decided to use it for, didn't perform well.
It's like buying small car and then being surprised that it doesn't have the same hauling power as a truck.
Frustratingly, everyone has taken it as gospel that it means AVX-512 is entirely crap and just going to hurt you.
It definitely has made optimising a bit more complicated. You could certainly argue that you might need to have the runtime profiling the code to figure out if using AVX-512 is harmful or not.
What happens when you have a vm on a core that's running avx-512? Will it also be down clocked? This is important to me since I'm orchestrating workloads on prem machines and my clients might want avx-512.
A core is a core... whatever is running on the core will be affected by the down-clocking. It's not possible for a single core to be operating at two different speeds simultaneously.
Note that a CPU can switch fairly quickly between different clock speeds. It's not instantaneous but it's pretty quick.
I'd encourage CPU pinning if you can (pinning each VM to a specific core). If you're depending on oversubscribing, that won't be possible, but presumably you'd already be expecting more of an impact from noisy neighbours anyway.
If somebody gives me a ThreadRipper I promised to do some performance investigations. I keep meaning to update my fractal program (Fractal eXtreme) to support more than 64 threads and that would give me a good excuse (processor group support is needed).
I'm really curious about the machine it's running on. 896 physical cores is an odd number - 32 x 28, 16 x 56 or 8 x 112 are the likely combinations. The picture identifies it as a Xeon Platinum 8180 which is a 28C/56T CPU. Are there systems that support 32 Intel CPUs in one host? I thought quad socket was the practical limit these days.
Thread affinities are tied to 64-bit numbers. So processor virtual cores are lumped into groups of at most 64. Threads can only be assigned to a single group at a time, and by default all threads in a process are locked to one group.
Well, each thread being only able to be scheduled on some of 64 cores hasn't been a huge issue so far. Usually you want your threads to stay in the same NUMA region anyways because cross socket communication is expensive.
Annoying if a processor group spans two NUMA regions leaving just a few processors to other side...
Well, I wouldn't advocate using Windows in such a setting...
I/O layer overhead in Windows is considerable. As any Windows kernel driver developer knows, passing IRPs (I/O request packets) through a long stack does not come for free. Not just drivers for filesystems, networking stacks, etc. and devices, but there are usually also filter drivers. IRPs go through the stack and then bubble back up.
Starting threads and especially processes is also rather sluggish. As is opening files.
There's no completely unified I/O API in Windows. You can't consider SOCKETs (partially userland objects!) as I/O subsystem HANDLEs in all scenarios and anonymous pipes for process stdin/stdout redirection are always synchronous (no "overlapped I/O" or IOCP possible).
For compute Windows is fine, all this overhead doesn't matter much. But I don't understand why some insist using Windows as a server.
But when someone pays me for making Windows dance, so be it. :-) You can usually work around most issues with some creativity and a lot of working hours.
The arguments I’ve heard are IO completion ports are less “brain dead” then epoll or select/poll and visual studio is a great IDE. Otherwise I’m not sure either.
IOCP is great, just annoying you can't use it with process stdin/stdout/stderr HANDLEs, at least if you do things "by the book". Thick driver sandwiches in Windows... not so great.
Visual Studio a great IDE... well, the debugger isn't amazing unless you're dealing with a self-contained bug (often find myself using windbg instead). Basic operations (typing, moving caret, changing tab, find, etc.) are slow at least on my Xeon gold workstation.
> I remember Linus playing around with a Xeon Phi CPU with a few hundred threads. The task manager was all percent signs.
The last Sun chips (Niagara / Ultrasparc Tx) also had pretty high count, IIRC they had 64 threads / socket, and were of course multi-socket systems. At 1.6GHz they were clocked pretty low for 2007 though.
Although this particular bout of verbalised obscenity did just make me change my default browser search engine to duck duck go as Google crossed out 'supercomputer' as missing from its query, which was annoying as it was 50% of my sodding query and, technically, the only correct bit. Google search is totally crap these days.
Oh, absolutely no worries! In older, smarter days (less smart, or at least less presumptive, perhaps?), I'd like to think that Google would've been clever enough to correct the incorrect aspect of my search term. As I say, this was the final nudge to move my standard search over to something else :)
That was the case of the original CMs (1/2/200), but the CM5 switched from the original single-bit processors to a lower number of RISC SPARC cores.
While it retained the LEDs, I don't think they had the same 1:1 correspondance to cores of the previous model: the CM1 and CM2 up to 65536 cores (the CM2 also had an FP coprocessor for 32 cores, for an additional 2048 special-purpose cores) whereas the CM5 had "only" 1056 processors.
The CM-5 LEDs had different settings options: on, disabled, and also a “random and pleasing” setting.
So in one respect, modern RGB LED motherboards utilize trickle-down supercomputer technology in the form of... blinkenlights.
A nicer UI trick would be to change how Windows Task Manager reports CPU usage on the "Details" tab, because with, e.g., 64 virtual cores, single-threaded process CPU utilization can only ever be 00, 01, or (assuming the display rounds up) 02, because the displayed value is
sum of core % utilization
-------------------------
number of cores
In a system with hundreds of cores, (predominantly) single-threaded processes' CPU utilization will therefore appear to be identically zero.
The "Processes" tab improves on this slightly by adding a single decimal digit, but this display still becomes less and less useful as core count increases because its precision remains inversely proportional to the number of (virtual) cores in the system.
Chrome changed their task manager to make the CPU percentages be relative to a single core instead of relative to the total CPU power available. This makes the numbers more comparable (100% on one machine is roughly the same as 100% on another, regardless of core count) and it avoids the problem of increasingly tiny numbers. Microsoft should follow that lead.
This change means that Chrome's task manager can show CPU usage percentages that are higher than 100%, but that is fine. The percentage is simply the percentage of a logical processor that is being used and 200% means that two logical processors are being used. Simple, easy to understand and explain.
macOS's Activity Monitor, and the task manager on Ubuntu (forgot its name, something like System Monitor maybe?) when in “Solaris mode” do sum of core % utilisation without dividing by number of cores. So a single core at 100% shows up as 100%, four cores at 100% shows up as 400%.
For a weird trick, change the decimal symbol and the digit grouping symbol to the same value in the Region settings in the old Control Panel. Then everything always uses 0% CPU :)
Works with the current 1:1 assumptions, but then the early windows performance problems with ryzen's NUMA design shows what happens when those assumptions are wrong. Their design, while less cool, is capable of handling pretty much any configuration.
And yet anandtech writes articles as though "home usees" and "gamers" have a user for these cores, despite benchmarks being the most demanding workloads those users will ever run on these machines.
In the "HEDT" space, the media coverage and forum chitchat is mostly for users who by these cards for decorative purposes, not work purposes. People buying for real work need realistic test measurements on realistic workloads.
Yeah, benchmarking the games is a little embarrassing. Outside of Twitch streamers who do software encoding on-device (which is a minority of a minority), almost everyone interested in game performance would be better served by a different market segment.
I guess it's driven by the types of hardware they normally review - their audience is interested in game benchmarks, so they might as well report them.
It’s not so unreasonable. I imagine there are plenty of users with HEDT workloads who also want to play games on the side, and want some assurance that their HEDT box can do both.
I mean nvenc has made a huge difference to streamers using nvidia cards already, you don't really need more than a 'consumer' 6C/12T or 8C/16T even with games gradually moving to supporting more cores if you have an nvidia card.
Prior to the very latest generation nvidia GPUs the quality of nvenc was significantly worse than software x264. This, along with the still there even if very small performance hit, is why the major streamers all still use a dual PC setup with capture cards.
If you're just streaming casually this doesn't matter at all. If this is your day job, though, you probably want all the quality & control you can get, and NVENC isn't quite there.
> Last AMD generation was 250W, this one is 280W: if we’re not there already, then this should be a practical limit.
A good point for people looking to use this in their home server like I am. It’s going to be really hot if you’re getting your money out of it.
At some point there’s not an efficient way to cool these processors when the ambient room temperature rises too high. Anyone have suggestions for that? I’m in a weird position where power is cheap but I can’t AC my garage (where it’s located).
How about some good old fans? I had a little NAS box in my garage for a few years that ran pretty hot and I was afraid of straining the hard disks. I ended up just using lm_sensors on the server to monitor temperature, and when it got it hot, kick off an SSH command to a raspberry pi sitting nearby to tell it to turn on an exterior fan (gpio -> mosfet -> relay) I had mounted to the side of the cabinet a few inches away from the server box (literally just an old PC fan).
Super ghetto but actually pretty efficient at bringing the server's temperature down.
I run a previous-generation 2990WX (320W TDP) and the largest Noctua air cooler is easily sufficient at a low fan speed. If it's in your garage and you don't care about fan speed, you should be able just to blast the fans faster and have a well-ventilated case before resorting to water cooling.
The cores start to throttle at 70C, which is far hotter than even the hottest garage.
> The cores start to throttle at 70C, which is far hotter than even the hottest garage.
Thermal dissipation however is proportional to delta-T (change in temperature).
A 25C ambient will provide delta-T of 45C, but a 35C ambient will provide a delta-T of 35C: so your 35C ambient garage will reduce performance by at least 22% compared to 25C.
----
Note that Intel chips can go all the way to 95C or 100C, making cooling a far easier problem. So you're already dealing with a lower Delta-T when you use these AMD chips that throttle at 70C. (To be fair: AMD and Intel's measurement systems are a bit different, so we can't compare them directly. But IIRC, most people have a slightly easier time cooling Intel chips).
Intel tends to cheap out on the connection to the heatsink (see overclocker forums for the complaints). Which actually results in a hotter CPU to dissipate the same watts.
AMD spent the extra few $ for a good thermal connection between the silicon and the heat spreader.
The new threadripper and Epyc chips are also physically quite large. It's much easier to cool the head spreader with 8 hot spots spread across the chip than a single smaller hot spot.
So generally it's easy to get 180 watts out of a threadripper/Epyc chips than the equivalent Intel. In fact some of the highest end chips are not considered feasible to cool on air. It's either water cooling of throttling, like in the new Intel based Frontera (don't confuse that with the AMD based Frontier cluster).
Basically keeping a dual socket Xeon 8280 cool without throttling is not practical on air.
The new 16 core Ryzen part already recommends a 280mm closed loop water cooler and so it doesn't come with a fan like the 12 core Ryzen does.
Finding an AIO with a waterblock that will cover a Threadripper is very difficult though. It's one of the reasons why I'm sticking with an overclocked 12 core Ryzen.
For TR4 at least, they're advertised as being compatible with the mount but the actual waterblock doesn't cover the whole processor.
AFAIK the Enermax TR4 is the only AIO that covers the TR4 but it has mold issues that cause it to degrade over a few months. It has 2 stars on Newegg right now.
> For TR4 at least, they're advertised as being compatible with the mount but the actual waterblock doesn't cover the whole processor.
For the first month or two after TR1 was released in 2017, it was true that the existing AIO blocks didn't cover the entire heat spreader, but they did cover all of the chiplets inside the heat spreader.
sTR4-specific AIO blocks came out within a handful of months. This hasn't been a problem for over a year.
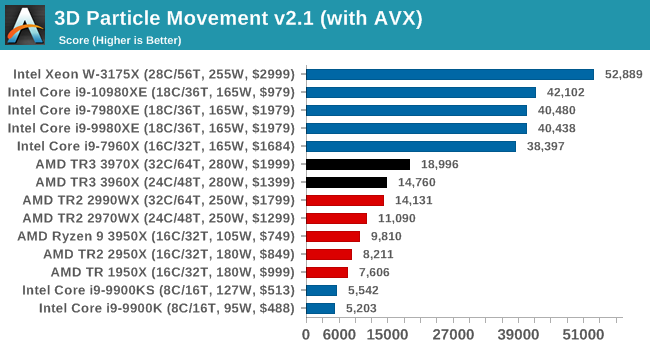
AMD is getting almost 30% better performance at 287 watts than Intel at 380 watts (Intel W-3175X in the review). If you're actually using all 32 cores all the time, you're saving TONS of money overall. Not only are you doing 30% more work, but at 25% less power.
Even if you left it on 24/7, it would take you a year and a half to make up the difference in price between the $2000 AMD and the $3000 Intel. If we assume both chips have identical performance, the Intel would cost $4350 to run over 5 years vs $3480 for the AMD (assuming 24/7 at all cores). The total cost of ownership for that Intel chip over 5 years seems to be around 2x that of the AMD chip.
I'd note we've been talking about 32 cores 24/7. If you're using 4 cores and 8 threads, you will be using half the power (about 140 watts). If your system is idling, it's using a bit less than 50 watts.
Let's say you leave your system on 24/7. You work 8 hours, play 4 hours (4 cores, 8 threads constantly running), and it idles the other 12 hours. We'll assume that you somehow max all cores for your entire workday and max 4 cores during play. You'd be well under half that price per month.
Change all-out time to a more reasonable, but still strenuous 4 hours with 8 moderate hours and shutting off your computer at night will get you down to less than $20 per month.
That's only if you use all cores 24x7 and all ALUs within those cores (vectorized workloads), which is very unlikely unless you're doing straight up linear algebra on the CPU.
In CA there's also the issue of not having electricity in the first place sometimes though. So power _consumption_ seems kind of secondary.
> That's only if you use all cores 24x7 and all ALUs within those cores
These chips don't run at a fixed frequency. They dynamically adjust based on thermal limits and power limits.
You only have to burden most of the cores/ALUs to hit maximum power. Any load above that threshold uses the same amount of power, as frequencies nudge down to compensate.
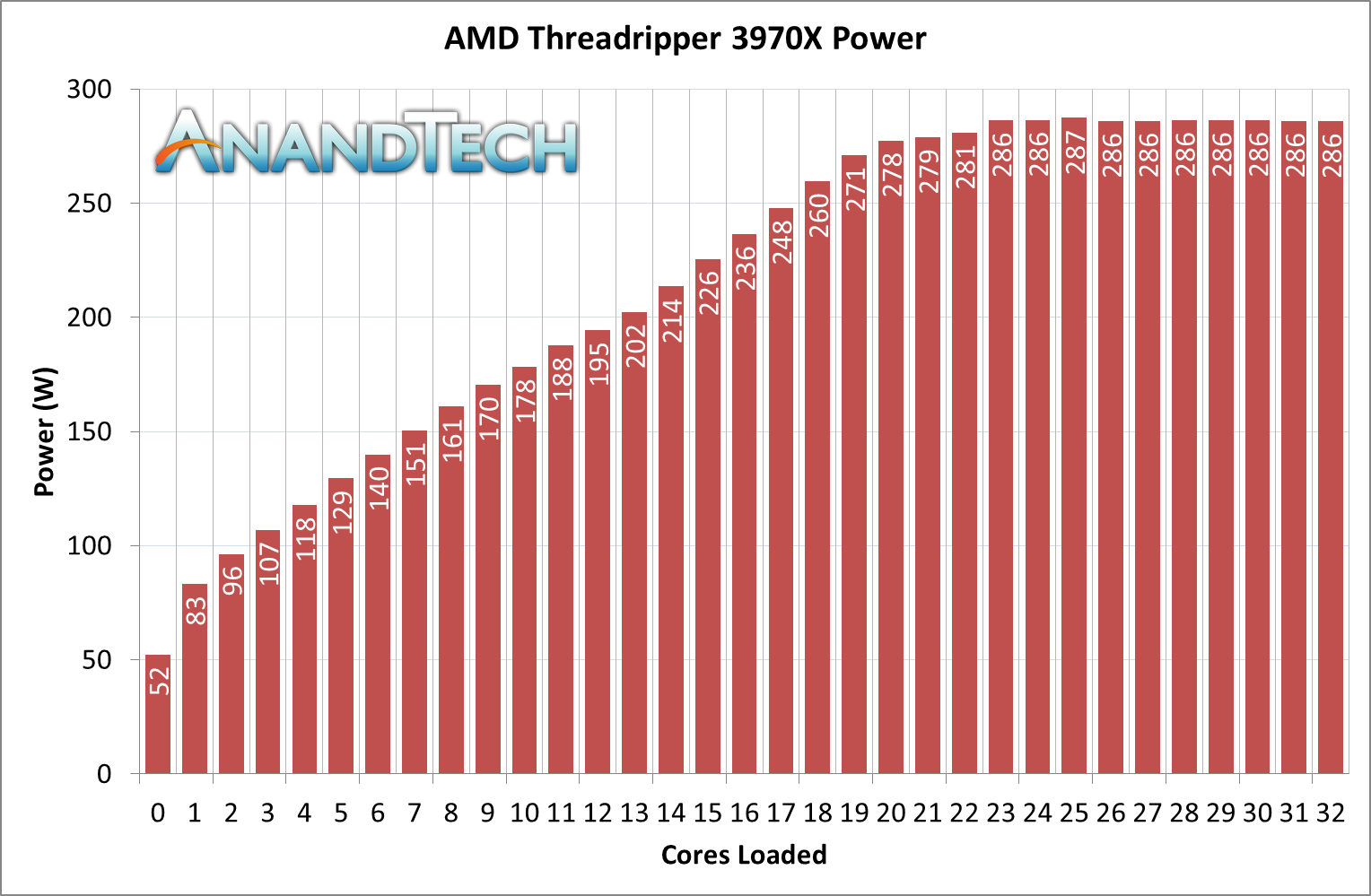
According to the linked Anandtech article, the maximum TDP is reached at ~22 cores fully slammed, yes. But it doesn't drop off much after that. But that's splitting hairs.
The power limit is configured in the BIOS, and can be disabled, but with these massive chips they default to throttling down and capping power consumption so that you aren't forced to go crazy with the cooling system (and motherboard and PSU capacity).
I’ve seen people on YouTube build a wood box around a small rack, put a bathroom fan inside, and run a foil hose for a dryer to the outside. The racks I saw already had a glass door so it was easier to build the sides and foil tap the cracks.
What temps you are getting? Are you looking tdie? Did you update bios? I am having 40~ tdie on 1950x with noctua air. (Even I clocked, disabled dynticks, have lot of pcie device and using quad channel). i think noctua is still competitive with water cooling on TR. I would recommend renew thermal paste, have a room inside of case, check negative/positive pressure and go through again your bios settings i.e. prevent clocking on load
Water cool it, maybe? Moving that kind of heat out of a regular heatsink is going to be extremely noisy and you'll be blowing a lot of hot air through your machine.
Personally I'm not that interested in extreme power at the cost of extreme heat. I'm more interested in enough power with as little heat as possible. I find it hard to figure out which processor is the best fit for that these days, but I guess this one isn't it.
Look into and get a split-unit ac. You can run the pipes quite a long distance, more than the advertising material and stock images would have you think! If power is cheap, you’ll regret not doing ten years ago.
Pioneer had the best bang-for-the-buck the last time I checked.
A few vendors make phase-change coolers which can activly cool below ambient. They're pretty expensive and niche and probably not reliable in the long term. Since it's going in the garage Id just get some really loud server fans.
You may not be able to AC your entire garage, but you could cool an entire rack with a rackmount AC unit (tripp-lite sells them). It costs more since you are constantly having to cool hot air as it comes in, so it's not an ideal solution from a performance or affordability perspective. You can buy ducts to push the heat out, but garages typically have poor insulation so ugh.
I live in Idaho and keep my 24U rack in my office, total idle draw on it is now around 4A@110V and considering power tops out at $0.11/KWh during the summer there's no real reason to colo it somewhere else.
I don't really see how the pricing is ridiculous though. They're still way cheaper than what Intel charged for the same cores a year ago, and they have more cores than Intel can even offer on their best workstation chips. If you compare against 28 core Xeons, the new Threadrippers are a downright bargain.
They are undercutting - on perf/$. The difference in sticker price you pointed out is only there because there is no comparable intel part (under $3000 at least)
I meant in comparison to what we were used to. Now a semi-decent TRX40 board is $700, entry-level TR3 is $1300. Top-end x399 board is $550, entry-level TR is $250. There was a huge jump in prices compared to previous generation of HEDT.
The price jump was +8% for 24 cores and +11% for 32 cores. It wasn't really a "huge" jump. The reason it seems so much more expensive is because the cheaper SKUs were simply removed instead of replaced.
And entry-level TR was never $250. That's the EOL "we need to dump old inventory" fire sale price.
Yeah, but everybody expected a price drop with new gen, instead we got overpriced TRX40 (compared to high-end x399) and the same number of cores for more $. I get it those cores are much more powerful, but it's still an untypical situation. 2990WX will probably stay at the same level as there is no other choice for x399 owners anyway.
I agree, but as an x399 2990WX will be the end of the line and therefore no reason to lower the prices, like was the case with 4790k. 2990WX loses many benchmarks to 3900x, 3960x should demolish it most of the time.
Reinforcement learning might be a good use case for 2990WX.
It seems like people benefit from the higher clocks and lower latencies from the 16-core 2950x. I pretty much consider the 2950x to be the end-of-the-line for typical use cases... with the 2990wx only really used for render-boxes.
> Reinforcement learning might be a good use case for 2990WX.
Hmm, the 2990wx is better than the 2950x for that task, but the 3960x has 256-bit AVX2 vectors. Since the 2990wx only has 128-bit AVX2 vectors, I would place my bets on the cheaper, 24-core 3960x instead.
Doubling the SIMD-width in such a compute-heavy problem would be more important than the +12 cores that the 2990wx offers.
EDIT: The 3960x also fixes the latency issues that the 2990wx has, so its acceptable to use the 3960x in general-use case scenarios (aka: video games). The latency-issue made the 2990wx terrible at playing video games.
Yeah, no one is buying these HEDTs for "purely" gaming tasks, but any "creative" individual who does video rendering during the week, but plays Counterstrike on the weekend, needs a compromise machine that handles both high-core counts AND high-clock speeds for the different workloads.
> but everybody expected a price drop with new gen
No they weren't. I certainly wasn't. There was no reason at all to believe TR3 would be a price drop. Ryzen 3000 wasn't and neither was X570. If the mainstream platform parts didn't get a price drop why would the HEDT halo products? Particularly since new generations are almost never price drops, especially without any competition?
> instead we got overpriced TRX40 (compared to high-end x399)
X399 at launch ranged from $340 to $550. TRX40 at launch ranges from $450 to $700. Yes there was a bump there, but there is also overlap in pricing, too. You are getting PCI-E 4.0 instead along with a substantially higher spec'd chipset. You're also getting in general a higher class of board quality & construction. Similar to the X570 vs. X470 comparison.
> but it's still an untypical situation
Untypical in that they are actually a lot faster generation over generation, sure. Untypical in that they are priced similarly or slightly more? Not really. That's been status quo for the last decade or so. The company with the halo product sets the price. The company in 2nd place prices cuts in response. AMD has the halo, they were never going to price cut it.
Top-end TRX40 is around $1000 (Zenith II). That's almost double of Zenith Extreme x399; x399 had 16-phase VRMs as well in later releases; PCIe 4's usefulness is questionable (basically just for 100 Gigabit networking right now).
For x399 users TRX40 is underwhelming as it just feels like "pay for the same stuff again" if you want to use new CPUs.
Halo boards are always stupidly overpriced. X570 tops out at $1000, too. That's a terrible way to judge a platform's costs.
> PCIe 4's usefulness is questionable (basically just for 100 Gigabit networking right now).
Not true at all. It's more bandwidth to the chipset, meaning you can run double the PCI 3.0 gear off of that chipset than you could before without hitting a bottleneck (well actually 4x since the number of lanes to the chipset also doubled...). That means more SATA ports. More M.2 drives. More USB 3.2 gen 2x2.
> For x399 users TRX40 is underwhelming as it just feels like "pay for the same stuff again" if you want to use new CPUs.
Not disagreeing on that but that's very different from TRX4 is "overpriced vs X399." Just because it's not worth upgrading to the new platform doesn't make the new platform overpriced vs. the old one.
> It's more bandwidth to the chipset, meaning you can run double the PCI 3.0 gear off of that chipset than you could before without hitting a bottleneck
Not necessarily the case in practice since that would require some sort of chipset or active converter exposed by the motherboard to mux 3.0 lanes to bifurcated 4.0 lanes. A 3.0 x4 device still needs those four lanes to get full speed so in a PCI-e 4.0 setting you’ll actually be using up four of the PCIe 4.0 lanes, but inefficiently.
This comment doesn't make sense. You're getting more cores than previous generation of HEDT, and the equivalent Intel processors aren't cheaper at all.
This is a new market segment. If you want a fast cpu, the Ryzen 7 and 9 series are completely fine if you want that price range!
The exact same price range as you're used to still exist.
On the other hand, people have been used to paying exorbitantly for Xeon processors, like 2000-5000 per cpu, so this is a breath of fresh air.
You are getting the same number of (better) cores for higher price. But backwards/forward compatibility is gone, so you either pay the full price upfront, or are stuck with outdated chips forever.
The bigger point is that there was no reason to kill X399 support at all. It's the same physical socket, the socket is capable of supporting much more than Threadripper did with it (Epyc uses the same socket for 8 memory channels), and the power consumption has not increased significantly compared to TR 2000 series.
There was no reason to kill TR4. It could have been a "legacy" board with PCIe 3.0 support, like X470 is for the desktop socket.
AMD just killed TR4 because they wanted everyone to buy new boards. The classic Intel move.
(meanwhile Intel put a new generation of chips on X299, while also putting out a compatible X299X socket that increases lane count. Intel doing it right for once, AMD doing it wrong for once.)
Which is kinda unnecessary as there is no single GPU on the market capable of saturating PCIe3 and situations where one needs a sustained transfer between multiple M.2 SSDs that could saturate PCIe4 are very rare. Only 100Gbps+ LAN is probably practical for a few total pro users.
Actually, its pretty easy to get bandwidth-bottlenecked in GPU-compute.
I know video games don't really get bandwidth bottlenecked, but all you gotta do is perform a "Scan" or "Reduce" on the GPU and bam, you're PCIe bottlenecked. (I recommend NVidia CUB or AMD ROCprim for these kinds of operations)
I pushed 1GB of data to device-side reduce the other day (just playing with ROCprim), and it took ~100ms to hipMemcpy the 1GB of data to the GPU, but only 5ms to actually execute the reduce. That's a PCIe-bottleneck for sure. (Numbers from memory... I don't quite remember them exactly but that was roughly the magnitudes we're talking about). That was over PCIe 3.0 x16, which seems to only push 10GBps one-way in practice. (15Gbps in theory, but practice is always lower than the specs)
Yeah, I know CPU / GPU have like 10us of latency, but you can easily write a "server" kind of CPU-master / GPU-slave scheduling algorithm to send these jobs down to the GPU. So you can write software to ignore the latency problem in many cases.
Software can't solve the bandwidth problem however. You gotta just buy a bigger pipe.
Yup. What's crazy is that a $6k 3990X is still a better deal in terms of $/core than even a dual-cpu Xeon W-3175 system (which would cost about $6k for only 56 cores).
probably closer to 3500-4000 USD. Maybe $5k if theyre feeling greedy. But I think they want to undercut intel so theyll keep their margins reasonable so they can crush the Xeon line
Ever since moving to Win 1909, our compile benchmarks have been a bit off. I was at Supercomputing last week, literally got back Saturday to start writing the review, and I need to get some time to debug why it's not working as it should. I've got Qualcomm's Tech Summit next week and IEDM the week after that, so you'll have to wait a bit. Ian (the editor of the review)
Consider adding Linux as the underlying platform for some of your tests. Not only it's usually easier to script repeatable developer-oriented workloads, but your reviews will be more comprehensive as well. The Linux scheduler is quite different and more advanced (as illustrated by vastly different Gen 2 Threadripper performance on Windows vs Linux), and your articles have not been capturing this.
I can see why Linux is not yet the mainstream for gamers, but this OS should be more popular among the HEDT crowd.
I can't resist asking something that's been bugging me for a long time. The issue of insane travel schedules has openly plagued AnandTech for a long time now, both delaying reviews and severely impacting their quality when they do come out. Every tech website out there covers the big events in roughly the same way, very few do proper deep dive technical reviews like you've done in the past. Is it really the best use of your time to (partially) squander the comparative advantage you have in favor of rushing from one event to the next, reporting the same things everyone else does?
His CPU reviews in particular have at times been virtually unparalleled in the industry. I don't think name recognition is an issue. It's just painful to see that suffer for run of the mill industry news reporting.
Quick question: How are you handling Intel's security patches vis-a-vis benchmarks/consistency? In particular as there are like three(?) performance impacting fixes now that were released over a two or more year period.
For example in articles like this where you include older chips are you just listing the numbers from previous benchmarks, or are all running on the same patch level/OS?
The percentage increase in performance in those benchmarks is stunning. They're pushing hard on the multi-thread end and it's clearly working for a lot of modern applications that can take advantage of it.
Pair one of these Threadrippers with a pair of the fastest NVMe SSD's out there, with plenty of high performance DDR4 memory and you've got a near supercomputer from recent past in terms of performance.
I just want vscode to work, because it's awesome when it does... but I tend to have 5-10 editors open at a time and so far only sublime_text works w/ my workflow without crashing...though it sometimes needs rebooted when the plugin manager is having race conditions or other errors. Plus other electron apps. Current system is about 8-10 years old though, upgrading after christmas sometime to 3700x amd line and ddr4 3200 ram 32gb (upgrading from 8gb)...mobo should be quite upgradeable though to last another decade.
> mobo should be quite upgradeable though to last another decade
Wouldn't count on it. I can't remember the specifics, but we're coming up on the end of the vague time range that AMD said they'd support the AM4 socket. They talked about how difficult and expensive it was to get the interposer to connect the new chiplets to the old pins on the socket. I think Lisa Su also implied in an interview that AM4 is nearing it's end. In any case, DDR5 is coming in the next year or two which would necessitate a new socket, so I'd guess one more generation on AM4 at most.
I'm getting MSI MPG 570x motherboard. It's upgradeable to 128GB, 3700x is pretty performant. I don't game. I use linux + i3wm. I simply want my code editors/browser windows to stop crashing lol...
My goal is a decent build < 1000. I already have a case/power supply. Just getting CPU, Mobo, RAM basically. Keeping my r9 270x amd gfx card from 2013. Normal cooling. My RAM can go higher than 3200, but price range 3200 seems best bang for buck, I figure when it comes down I could upgrade to 128GB @ 4400 and eventually the cpu to whatever the highest end am4 socket allows, and a better graphics card and get a few more years out of my system.
I've never spent more than 800 on a system. I guess one man's 'wow this is cool' is another's 'no, that's lame' lol.
Elsewhere, Zen 3 has been rumored to be a full rewrite, i.e. a new microarch from the ground up. That doesn't jive well with maintaining socket compatibility with AM4.
The words I've seen from AMD on this matter seem fairly clear that they intend to keep Zen 3 on AM4. Most likely they'll wait until Zen 4 on a 5nm process to switch to a new socket(in 2021).
It's still a 'bit' upgradeable. But I think RAM/Gfx will get me further over the next 7-8 years in terms of speed/etc. It's a decent build comparable to maybe a $2000+ consumer desktop for $699. For my use case It'll fly compared to my system now which bogs down when I have 126 browser tabs open.
Gamers Nexus did some GCC benchmarks with the regular Ryzens and indeed they were absolutely trouncing intel, and indeed it was due to the big l3 cache.
The Threadrippers are the same cpu with just more of them so I'm sure they do well also.
That is insane. I'm surprised it can even go that low, I would have expected it to hit an IO bottleneck before then (large object files/linking/source reads, etc).
Even with a fast SSD on my lowly i7, I often wind up sitting at IO or lock contention instead of actual CPU bottlenecks (although it could be argued faster CPU = faster lock release = faster compilation).
I've done builds in /dev/shm/ on Xeon and Threadripper with only a trivial speed-up. If it can fit in tempfs, make/cc can just load it all into RAM anyway, so I guess you only reduce the build time by the time it takes for the first read. Which would explain why '-j' on a big codebase tends to trigger my OOM killer.
Technically, 100%. I'm full SSD right now though which has a seriously noticeable difference from from HDD but for what I do most days NVME isn't justifiable. I see others who can take advantage of the speeds and do so with huge returns.
I do have 2 super SFF HP boxes that only take NVME in the M.2 drive so have one on hand but it isn't installed at the moment.
That's just four SSDs mounted on one riser card with a fan. If you're going to count the aggregate bandwidth of an array, then the question's almost meaningless.
"Also, our compile test seems to have broken itself when we used Windows 10 1909, and due to travel we have not had time to debug why it is no longer working. We hope to get this test up and running in the new year, along with an updated test suite."
This is my frustration with almost all tech sites. The AMD press deck included compilation benchmarks, but the only others to reliably provide them are Phoronix.
Most reviewers don't bother doing compile benchmarks because they're not as familiar with them and perhaps they don't come in the same "canned" form as every other gaming benchmark. It may also be that each site caters to a particular audience.
On the other hand bench results have to be comparable and relevant (in time). Which is easy when you run the same still widely played GTA V year after year on every new CPU. But comparing compilation time for kernel version 3.11 (released at the same time as GTA V) seems a lot less relevant today.
Maybe this would change if someone would pre-package a build environment with source code, a nice gui and fancy abstract visualization of the compile process.
Phoronix does do this, but it's unfortunately harder to use than would be required for wide adoption in the press. It really has to be as simple as downloading an exe that pops up a window with a "go" button when run, and has to show some nice things happening on screen. Game and graphics benchmarks do this, so that's what they use.
It's been a while since the L1 cache size (64KB) has exceeded that of my first computer. What I find crazy is that a single Ryzen core has more in registers than some of the computers I've used.
AMD64 has 16 64 bit registers, but Ryzen actually has 168 behind the scenes so it can pipeline and reorder multiple instructions simultaneously. That's almost 1.5KBytes of memory, more than some microcontrollers have in ROM or RAM.
It's actually a lot larger if you look at vector registers - AVX registers are 32 bytes each and there are also ~168 of them in modern AMD and Intel CPUs, resulting in 5KB of registers. With AVX-512 the number is 10KB!
I got a 1tb SSD. I remember a time when 250mb Zip Drives were the stuff of science fiction, or when I thought they'd never top the 128mb storage on my first digital camera.
They have server and workstation parts up to 28 cores, but their enthusiast-oriented product line is 10, 12, 14 or 18 cores while AMD offers 16, 24, 32 and soon 64.
Sure, but AMD has a 16-core part on their mainstream socket that is in the same price range as Intel's 14-core HEDT part, and the AMD chip is performance competitive with the Intel HEDT parts despite being limited to two memory channels.
> Thread + Ripper was a clever play on words: anything that had plenty of threads, the hardware was designed to ‘rip’ through the workload.
Tangent, but is this really a play on words? And if so, what is the other meaning here?
I get the meaning where lots of cores are ripping through workload. But the other one I don't. The closest guess I have is that it's like a comic book hero (The Incredible Hulk) ripping through his clothes because he is so big and powerful. And I don't guess it refers to a seam ripper (the sewing tool).
There is a tool that your grandmother probably used a lot called a seam ripper. You stick the end of it into a seam and pull down and it cuts all the threads that make the seam.
AMD's (and Intel's) marketing teams are awfully enslaved to the gamer market - gamer aesthetics, big bold packaging, insane names that sound like something off of Tron, the whole RGB enchilada.
AMD started it with Ryzen. That name sounds like a character from the Lord of the Rings. And then we Threadripper - violent to say the least, and finally, EPYC - cheap play of the letters.
What happened to marketing like the IBM System 360? Elliot Noyes is rolling in his grave. I don't think the marketing teams are to be blamed, its the consumers and the Taiwanese influence around what a computer product should be marketed as such.
I guess I never thought of it in a gaming-oriented way, although it totally makes sense.
Ryzen also sounds like "rising", and even like "horizon", which are both pretty positive and non-gamer-y.
Ripping has other meanings too. It can mean going really fast or energetically, like "the driver ripped right past the race leader on that corner" or "let her rip" when you launch something at full speed. And a sawmill or woodworker uses a circular saw, band saw, etc. to rip wood, which means dividing it along the grain, the natural direction it wants to split. Which I suppose makes a good analogy for embarrassingly parallel compute problems.
Ryzen is hardly any worse than Itanium, Solaris, EPIC, all names of products marketed at businesses in the past.
Personally, I appreciate the optimism (correctly as it turned out) that it would be the line to turn AMD's fortunes around.
I think you've let your perception of the names be affected by the marketing. e.g. the X Box 360 could be the name for a boring server (maybe someone's tenth gen), but instead it's a game console. PS5 and Core are pretty descriptive name compared to the business product names previous.
They're marketing to the people who are affected by such marketing. I'd like to think the rest of us ignore any marketing and choose their CPU's for better reasons.
Has anyone seen independent reviews for database performance on EPYC 2 / Threadripper 3?
I'd love to recommend the AMD platform for customers with large databases, but there's is zero reputable information available on the Internet. The vendors can't be trusted, because they obviously cheat their ass off, such as Intel disabling security patches, using ludicrous hardware configurations, etc...
Don't forget that if comparing to old benchmarks, there's a bug with Intel's TSX now and the mitigations once again seem to take a nice hit if your database engine makes use of it.
For what databases? Many vendors specifically disallow publishing any benchmarks in their licensing, so if you're looking for benchmarks for a proprietary database, good luck.
>That's more than what a large refrigerator uses ..
That's partially due to good insulation in modern fridges. After all, if the insulation is perfect, you could run a fridge on 0W (assuming you don't open the doors).
Watts are joules/second - with perfect insulation and doors not opening, the only energy used is the energy used to cool the contents initially. As time approaches infinity watts approach zero, despite the energy consumed initially. c/t -> 0 as t->INF given constant c.
Anandtech's testing showed full load power consumption of 279.82 W (3960X) and 286.72 W (3970X). OTOH the "255W" Xeon W-3175X full load power consumption was 381.08W...
Overclocking chips does tend to cause power usage to spike, yes. That's not exactly a new thing, nor is the increase that surprising. A slight bump to voltage will cause power consumption to skyrocket. Heck, i9-7980XE's at 4.9ghz are pushing 1kW in consumption. Hence why intel's 28 core @ 5ghz demo used a 1700W capable cooler.
The power consumption of an individual core can vary greatly depending on its clock speed (and voltage, which can be reduced when running at a lower clock speed). Putting 64 cores into the same TDP as their 32-core chip is actually pretty easy. If you actively use all 64 cores, they'll be running at a lower clock speed than if you were only using 32 cores.
TRX40 can do only as much RAM as x399 (256GB) as there are only 32GB (ECC) UDIMMs available. With incoming 64-core TR that would be 4GB/core or 2GB/thread, which is way too little for a CPU that would cost ~$5k. TRX40 boards also for some reason have fewer PCIe slots (4) than x399 (6) or x299 (7) boards. I can't call them "Pro" because of that - fewer GPUs for Deep Learning is not a good idea in a workstation-level tech.
The benchmarks on the Ryzen Threadripper and Zen 9 3rd gen cpus look great. I have been looking to find prebuilt gaming desktops that don't have issues with those chips. Newegg reviews show failures around their units and Amazon isn't much help either. Is this truly a build your own situation? Not necessarily issues with the CPUs but the overall quality of the build and bios issues/DOA status. Any recommendations for BYO or prebuilt options?
Honestly, anyone with the know how to build their own PC should. The savings are not only substantial (usually, unless you find some crazy black friday discount), you can actually spec it to what you actually need.
Pre-builts usually have an over-specced CPU and and under-specced GPU, a bad memory configuration, crappy hard drives, and horrible power supplies + motherboards.
it'd be funny if amd came out with something like intel phi pcie cards, after intel discontinued them. But for my mostly unet / fcn, segmentation deep learning models, gpu's will continue to be the goto, until we get into a few hundred cores range...
I started wondering about the physics of removing 280W of heat from the tiny silicon die/dice. Is most of the heat conducted through the metal connections or through the package? What material is the package made of?
The lid is made of copper and as you see there are additional layers. Plus the interfaces between the materials are also limiting thermal conductance. As far as material science goes there's a lot of room, it's just not practical to throw liquid nitrogen cooling or diamond substrates at the problem when you're making a mass market product.
They use a heatspreader (solid metal surface, the "top" of the chip) soldered to the actual cores. Then you slap a heatsink or water block on and tighten it down on the heatspreader with the help of a thermal interface material (metallic goo). The actual cooling done by the heatsink or water cooler is pretty basic and similar to what you'd find inside cars or home A/C units.
With "280 watts" you can still use an off-the-shelf Noctua air cooler or any number of all-in-one water coolers.
32 cores at good price point. Now there's no reason to lease all those VM's and use kubernetes. Unless of course, we are all I/O bound due to the bulk of the work being telemetry and tracking. hmm....
An advice for the younger enthusiasts out there: don't buy this _yet_, it's an overpriced pseudo-workstation platform for now, even if you can afford it.
It's nice to watch (and have) new CPUs pushing the available computing performance up, and bringing new features. With Ryzen 3000/EPYC Rome this finally happened in a meaningful way, and TR is(shortly will be) the most powerful CPU there is. _AND_ Intel is getting kicked in the ass, which is good.
But objectively, even if AMD is better value than Intel now, it still is overpriced.
The first problem is with the launch price. This kind of system maintains the top status for one year or so these days. Then it slips into mainstream level which can be got for 50%, 30% price. Look at what happened to 2950X, or EPYC Milan platforms. They were similarly expensive at launch and they are mainstream performance now, their prices have fallen dramatically as well. (If you want AMD, those are much better choice now.)
The second problem is, the TRX40 motherboards available now are simply underwhelming and disappointing, take a look:
You can get 16,24,32 cores for x $1000, but only 4 channels of memory and 3-4 PCIe slots and 2010-era networking? The Xeon workstation boards are so much better. Here is how you design a motherboard in this price range:
The result for me is, if you're after performance but clever with money, go for 3900X or 3700X on an B450 board, anything else is kind of stupid for most people.
If you're after solid workstation with ECC and 2020-level, connectivity, Intel Xeon W now or wait for better motherboards (unlikely to happen).
I think this is the part where it gets interesting. Once you have enough parallel general-purpose compute horsepower available to run a physically-based renderer (e.g. what Pixar uses) at frame rates beyond 30/second, you can start to enter into a realm of arbitrarily-complex scenes within real-time applications.
How far off are we from this possibility, assuming someone sat down and optimized existing solutions for this use case?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}