Hi HN! Dmitry and Ryan here. We're building Pyroscope (
https://pyroscope.io/) — an open source continuous profiling platform (
https://github.com/pyroscope-io/pyroscope).
We started working on it a few months ago. I did a lot of profiling at my last job and I always thought that profiling tools provide a ton of value in terms of reducing latency and cutting cloud costs, but are very hard to use. With most of them you have to profile your programs locally on your machine. If you can profile in production, you often have to be very lucky to catch the issues happening live, you can't just go back in time with these tools.
So I thought, why not just run some profiler 24/7 in production environment?
I talked about this to my friend Ryan and we started working. One of the big concerns we heard from people early on was that profilers typically slow down your code, sometimes to the point that it's not suitable for production use at all. We solved this issue by using sampling profilers — those work by looking at the stacktrace X number of times per second instead of hooking into method calls and that makes profiling much less taxing on the CPU.
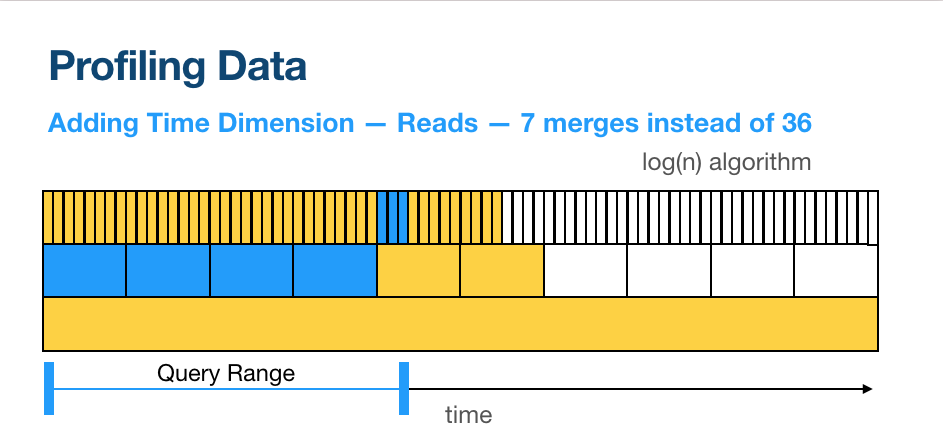
The next big issue that came up was storage — if you simply get a bunch of profiles, gzip them and then store them on disk they will consume a lot of space very quickly, so much that it will become impractical and too expensive to do so. We spent a lot of energy trying to come up with a way of storing the data that would be efficient and fast to query. In the end we came up with a system that uses segment trees [1] for fast reads (basically each read becomes log(n)), and tries [2] for storing the symbols (same trick that's used to encode symbols in Mach-O file format for example). This is at least 10 times more efficient than just gzipping profiles.
After we did all of this we ran some back of the envelope calculations and the results were really good — with this approach you can profile thousands of apps with 100Hz frequency and 10 second granularity for 1 year and it will only cost you about 1% of your existing cloud costs (CPU + RAM + Disk). E.g if you currently run 100 c5.large machines we estimate that you'll need just one more c5.large to store all that profiling data.
Currently we have support for Go, Python and Ruby and the setup is usually just a few lines of code. We plan to release eBPF, Node and Java integrations soon. We also have a live demo with 1 year of profiling data collected from an example Python app https://demo.pyroscope.io/?name=hotrod.python.frontend{}&fro...
And that's where we are right now. Our long term plan is to keep the core of the project open source, and provide the community with paid services like hosting and support. The hosted version is in the works and we aim to do a public release in about a month or so.
Give it a try: https://github.com/pyroscope-io/pyroscope. We look forward to receiving your feedback on our work so far. Even better, we would love to hear about the ways people currently use profilers and how we can make the whole experience less frustrating and ultimately help everyone make their code faster and cut their cloud costs.
[1] https://en.wikipedia.org/wiki/Segment_tree
[2] https://en.wikipedia.org/wiki/Trie
{kind=link}
I love the fact that this is out! I have been the original author of vmprof and I have been working on profilers for quite some time. I'm also one of the people who worked on PyPy. We never managed to launch a SaaS product out of it, but I'm super happy to answer questions about profiling, just in time compilers and all things like that! Hit me here or in private (email in profile)